تا به حال با خودتان فکر کردهاید که یک برنامه دیجیتال در کامپیوتر یا گوشی چطور میتواند زبان ما را بفهمد؟ پردازش زبان طبیعی (NLP) تکنولوژیای است که به کامپیوترها این امکان را میدهد که زبان انسان را درک کنند و با او به تعامل بپردازند. این فناوری در بسیاری از برنامهها و ابزارها، از جمله چتباتها و دستیارهای صوتی، به کار میرود و کمک میکند تا ارتباطات انسانی به شکل طبیعیتری برقرار شود.
تصفیه متن
مرحله اول پردازش زبان طبیعی (NLP) ، تصفیه متن است که باعث پالایش متن خام میشود. در این مرحله، بخشی از واژگان حذف میشوند یا تغییر میکنند. علاوه بر این، موارد نگارشی از جمله حذف علائم بیتأثیر، حذف فاصلههای اضافی، حذف ایموجیها، حذف حروف اضافه، اصلاح اشتباهات تایپی و حذف آدرس سایتها و نامهای کاربری در این مرحله انجام میپذیرد.
تجزیه و تحلیل لغوی یا توکن سازی
مرحلۀ دوم در پردازش زبان طبیعی (NLP)، تجزیه و تحلیل لغوی است که به عنوان یکی از مهمترین مراحل این فرآیند شناخته میشود. در این مرحله، متن ورودی برای پردازش دقیقتر آماده میشود و شامل چندین فرآیند کلیدی است که به درک بهتر محتوای متن کمک میکند.
توکنسازی
یکی از اساسیترین مراحل تجزیه و تحلیل لغوی، توکنسازی است. در این فرآیند، متن به واحدهای کوچکتر و قابل فهم برای کامپیوتر تبدیل میشود. این واحدها به نام توکن شناخته میشوند و میتوانند شامل واژهها، اعداد، و علائم نگارشی باشند. توکنسازی به شکل زیر انجام میشود:
- شناسایی توکنها: در این مرحله، نرمافزار متن را تجزیه و تحلیل کرده و به شناسایی توکنها میپردازد. هر کلمه، عدد و علامت نگارشی به عنوان یک توکن مجزا شناسایی میشود.
- فصلبندی متن: متن به جملات و کلمات تقسیم میشود تا ساختار آن بهتر قابل فهم باشد. این کار به کامپیوتر کمک میکند تا هر توکن را بهصورت مجزا بررسی کند.
- حفظ ترتیب: در طول توکنسازی، ترتیب توکنها در متن اصلی حفظ میشود. این موضوع اهمیت زیادی دارد زیرا ترتیب واژهها میتواند معانی مختلفی را به وجود آورد.
تجزیه و تحلیل لغوی و توکنسازی به کامپیوتر این امکان را میدهد که به دقت متن را پردازش کرده و تحلیلهای معنایی و نحوی را بر اساس توکنهای شناساییشده انجام دهد. این مرحله به ایجاد پایگاهی برای مراحل بعدی پردازش زبان طبیعی کمک میکند و به مدلهای یادگیری ماشین اجازه میدهد که بر اساس دادههای دقیقتر و ساختارمندتر آموزش ببینند.

کدگذاری کلمات (Word Embedding)
مرحلۀ سوم در پردازش زبان طبیعی (NLP)، کدگذاری کلمات (Word Embedding) است. در این مرحله، توکنها با ارزشهای عددی تعریف میشوند که به کامپیوتر کمک میکند تا کلمات را از زبان طبیعی درک کند.
مفهوم کدگذاری کلمات
کدگذاری کلمات فرآیندی است که در آن هر کلمه به یک بردار عددی تبدیل میشود. این بردارها به گونهای طراحی شدهاند که ویژگیها و روابط معنایی بین کلمات را منعکس کنند. به عبارت دیگر، کلمات مشابه در معنای خود، به بردارهای نزدیک به هم در فضای چندبعدی تبدیل میشوند.
مزایای کدگذاری کلمات
- درک معنایی: با استفاده از کدگذاری کلمات، کامپیوتر میتواند روابط معنایی بین کلمات را بهتر درک کند. مثلاً کلمات “پادشاه” و “ملکه” ممکن است به بردارهای نزدیک به هم تبدیل شوند، زیرا هر دو به مفاهیم سلطنت و حکمرانی مرتبط هستند.
- کاهش ابعاد: کدگذاری کلمات به کاهش ابعاد دادهها کمک میکند. به جای استفاده از یک نمایش متنی از کلمات که میتواند بسیار بزرگ باشد، میتوان از بردارهای عددی با ابعاد کمتر استفاده کرد.
- تحلیل و یادگیری بهتر: مدلهای یادگیری ماشین میتوانند با استفاده از این بردارهای عددی به تحلیلهای دقیقتری بپردازند و عملکرد بهتری در وظایف مختلف NLP مانند دستهبندی متن، تشخیص احساسات و ترجمه ماشینی داشته باشند.
روشهای متداول کدگذاری کلمات
برخی از روشهای معروف کدگذاری کلمات شامل Word2Vec، GloVe و FastText هستند. هر یک از این روشها از الگوریتمهای خاصی برای تولید بردارهای عددی استفاده میکنند و ویژگیهای خاص خود را دارند.
بهطور کلی، کدگذاری کلمات یک مرحله حیاتی در پردازش زبان طبیعی است که به کامپیوتر کمک میکند تا با دقت و کارایی بیشتری با زبان انسانی تعامل داشته باشد و به درک عمیقتری از متن دست یابد.

طبقه بندی متن
طبقه بندی متون مرحله چهارم از مراحل پردازش زبان طبیعی است که در آن، دادهها برای آموزش یک مدل یادگیری ماشین (Machine learning) و یادگیری عمیق (Deep learning) آماده میشود. در مرحله آخر، آمادهسازی داده، انتخاب و آموزش مدل، بهینهسازی مدل و در نهایت راهاندازی آن انجام میپذیرد. برای مرحله یادگیری ماشین، با هدف بهبود کارایی کامپیوتر که به طور مداوم با دادههای متعدد آموزش میبیند، با تکیه بر مجموعهای از تکنیکهای آماری برای شناسایی بخشهای مختلف متن، گفتار، احساسات و دیگر جنبهها، راه را برای پردازش زبان طبیعی در تجزیه و تحلیل متون هموار میکند.
کاربرد پردازش زبان طبیعی
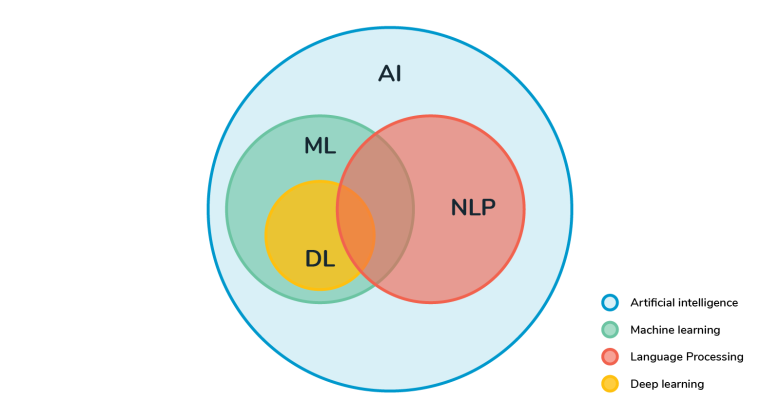
پردازش زبان طبیعی را میتوان شاخهای از سه حوزه علوم کامپیوتر، هوش مصنوعی و زبانشناسی دانست که به ابزارهای دیجیتال این امکان را میدهد که با انسان تعامل کنند. پردازش زبان طبیعی کاربردهای متنوعی دارد که در ادامه به چند مورد از آن اشاره میکنیم.
- درک و تفسیر زبان انسان: با توجه به گذراندن مراحل تصفیه متن، توکنگذاری، تجزیه و تحلیل معنایی و کدگذاری کلمات این فناوری میتواند معنای جملات را درک کند و به این ترتیب زبان انسان را بفهمد.
- پردازش گفتار: در برنامههایی که به پردازش گفتار برای تبدیل گفتار به متن نیاز است، از پردازش زبان طبیعی بهره گرفته میشود.
- ترجمه ماشینی: در رمزگذاری و رمزگشایی ترجمه خودکار یا ماشینی، پردازش زبان طبیعی الزامی است.
- تحلیل احساسات: تحلیل احساسات کاربر از روی متن یکی از پیچیدهترین کارهایی است که ماشین باید انجام دهد و این موضوع ارتباط مستقیم با پردازش زبان طبیعی دارد. ابزارهای تحلیل احساسات به کمک درک معنای واژگان میتوانند بسیار تاثیرگذار باشند.
- تجزیه و تحلیل کسبوکار: برای دستیابی به درک بهتر و تخصصی از عملکرد مشتریان نسبت به محصولات و خدمات، ابزارهای مبتنی بر پردازش زبان طبیعی بسیار کاربردی است. برای این منظور ابزارهای هوشمند متعددی وجود دارد که میتواند لحن و احساس مخاطب را در گفتوگوی متنی کشف کند که مدیر فروش یا بازاریابها را مطلع کند.
- تعامل بهتر با مشتری: در تجارت همیشه ارتباط با مشتری نقش بسیار مهمی در موفقیت کار دارد. پردازش زبان طبیعی برای این به کار میرود که میتواند رفتار چتباتهای متنی و صوتی را بیش از پیش به انسان شبیه کند و به این ترتیب کیفیت خدماتدهی به مشتریان را افزایش و هزینههای عملیاتی را کاهش دهد.

در نهایت، میتوان پردازش زبان طبیعی را یکی از حوزههای مهم هوش مصنوعی دانست که امکان درک زبان انسانی را در کامپیوتر ایجاد میکند. این تکنولوژی در آینده در دستیابی انسان به تکنولوژیهای بزرگتر از آنچه امروز به دست آمده، کمک خواهد کرد. علاوه بر مترجمهای دیجیتال در این زمینه، از ابزارهای تحلیل احساسات پیشرفته، برنامههای تبدیل متن به گفتار لحظهای، چتباتهای مولد پیشرفتهتر و دستیاران صوتی هوشمندتر نیز میتوان نام برد.