در مقالات تاثیرات هوش مصنوعی بر صنعت زیبایی، چالشهای اینترنت اشیای پزشکی و سیستم آبیاری هوشمند، کاربردهای مهمی از هوش مصنوعی را خواندیم. در این مقاله میخواهیم به شاخهای از هوش مصنوعی بپردازیم که پردازش زبان طبیعی (NLP)شناخته میشود و بر آموزش کامپیوترها برای درک و تقلید زبان انسانی با استفاده از تکنیکهای مختلف، از جمله الگوریتمهای یادگیری ماشین، تمرکز دارد.
تاریخچه پردازش زبان طبیعی
تاریخ پیدایش پردازش زبان طبیعی (NLP)، به دهه 1950 باز میگردد که یکی از نقاط عطف مهم این سال بود. دانشمند کامپیوتر و ریاضیدان آلن تورینگ بازی تقلید (imitation game)، که تست تورینگ نیز شناخته میشود را پیشنهاد کرد. با آموزش یک کامپیوتر، ارتباط بین انسان و کامپیوتر تسهیل میشود و بهرهوری فرآیندهای کاری بهبود مییابد. سازمانها از پردازش و تفسیر زبان طبیعی (Natural language processing) برای تحلیل و آگاهی از دادههای طبیعی ساختار یافته و غیرساختار یافته، مانند ایمیلها، اسناد و مقالات استفاده میکنند.
پس از دهه 1950 تا دهه 1990، پردازش زبان طبیعی عمدتاً بر روشهای مبتنی بر قوانین متکی بود، جایی که سیستمها با استفاده از قوانین زبانی دقیق برای شناسایی کلمات و عبارات آموزش میدیدند. با شهرت یادگیری ماشین (ML) در دهه 2000، الگوریتمهای یادگیری ماشین با پردازش زبان طبیعی تلفیق شدند و امکان ایجاد و توسعه مدلهای پیچیدهتر را فراهم کردند.
تکنیکهای پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) از دو تکنیک اصلی استفاده میکند:
- سینتکس syntax: تکنیکهای مبتنی بر سینتکس بر تحلیل ساختار جملات برای شناسایی الگوها و روابط بین کلمات تمرکز دارند که شامل تحلیل ساختار دستوری، بخشبندی کلمات (تقسیم متن به کلمات منفرد)، شکستن جملات (تقسیم متن به جملات)، و ریشهیابی (حذف پسوندهای مشترک از کلمات) میشود.
- معناشناسی semantics: تکنیکهای معناشناسی به فهم معانی کلمات و جملات میپردازند که شامل تشخیص معنای کلمه (تعیین معنای مرتبط کلمه در یک زمینه خاص)، شناسایی اسامی خاص و مفاهیم کلیدی، و تولید زبان طبیعی (ایجاد متن شبیه به متن تولید شده توسط انسان) میشود.
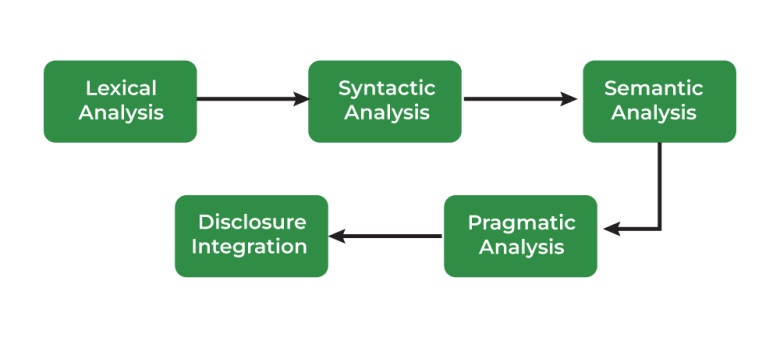
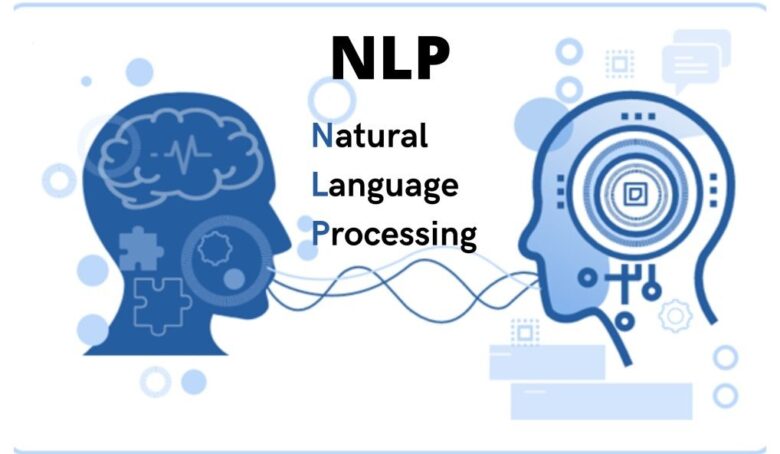
مراحل پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) دو مرحله اصلی دارد:
اولین مرحله آن پیشپردازش دادهها است. جایی که دادهها برای تجزیه و تحلیل آماده میشوند. در واقع هر نوع پردازشی را که بر روی دادههای خام انجام میشود، توصیف میکند تا آن را برای پردازش داده دیگر آماده کند. این رویکرد به طور سنتی یک مرحله مقدماتی مهم برای فرآیند داده کاوی بوده و اخیراً، از این تکنیکها برای آموزش مدلهای یادگیری ماشین و مدلهای هوش مصنوعی استفاده میشوند. پیش پردازش داده، دادهها را به قالبی تبدیل میکند که در دادهکاوی، یادگیری ماشین و سایر کارهای علم داده پردازش آسانتر و مؤثرتری اتفاق بیفتد.
تکنیکهای مهم برای آمادهسازی دادهها را میتوان به این صورت لیست کرد:
- استخراج موجودیت: شناسایی بخشهای مرتبط از اطلاعات درون متن.
- ریشهیابی: تبدیل کلمات به شکل پایه یا ریشه آنها که به آن لمما lemma گفته میشود.
- برچسبگذاری نقش دستوری: تعیین نقش دستوری هر کلمه.
- حذف کلمات توقف: حذف کلمات رایج و بیاهمیت.
- نشانهگذاری: شکستن متن به واحدهای کوچکتر مانند کلمات، عبارات یا هجاها که به آنها tokens گفته میشود.
مرحله دوم پردازش زبان طبیعی، توسعه الگوریتم است که شامل دو بخش بر اساس قوانین و یادگیری ماشین میشود.
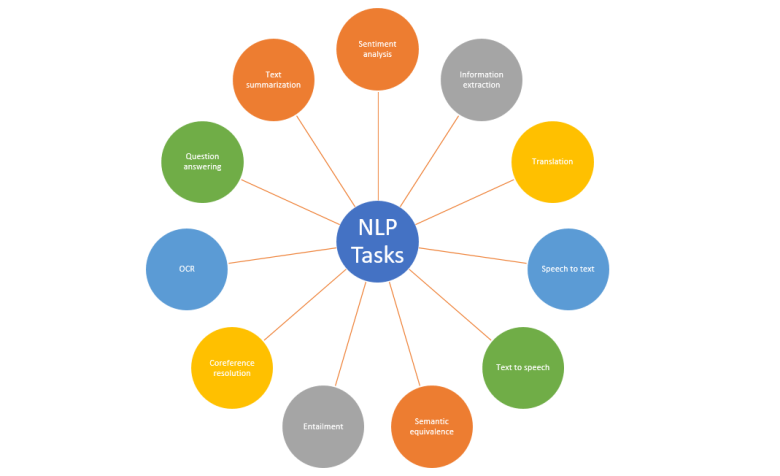
کاربردهای پردازش زبان طبیعی
پردازش زبان طبیعی بیشتر در سیستمها و ابزارهای هوش مصنوعی که نیاز به درک و استفاده از زبان طبیعی دارند، به کار میرود.
- تجزیه و تحلیل و دستهبندی دادههای متنی
- بررسی دستور زبان و تشخیص سرقت ادبی
- تولید و ترجمه زبان
- تحلیل احساسات
- تشخیص اسپم
- تشخیص صوت و صدا
در نهایت، پردازش زبان طبیعی یکی از حوزههای مهم در زمینۀ هوش مصنوعی است که امکان درک زبان انسانی را در کامپیوتر ایجاد میکند. این تکنولوژی در آینده در دستیابی انسان به تکنولوژیهای بزرگتر از امروز نقشی اساسی خواهد داشت. علاوه بر مترجمهای دیجیتال، ابزارهای تحلیل احساسات پیشرفته، برنامههای تبدیل متن به گفتار لحظهای، چتباتهای مولد پیشرفتهتر و دستیاران صوتی هوشمندتر نیز از جمله کاربردهای پردازش زبان طبیعی خواهد بود.